30天系列 Day 15-Apache Spark 簡介
Apache Spark 簡介
目前Big data最熱門的open source專案莫過於Apache Spark。為什麼Spark會這麼受歡迎?原因有三個:速度、速度與速度,是的!沒看錯就是速度。當初Hadoop正式釋出後造成轟動,一個跨世紀的儲存、運算、資源管理的平台誕生了,但由於MapReduce運算花費太多的磁碟IO,造成運算效能與使用者的期待落差甚遠,所以Spark推出後就因為他的運算速度而快速吸引眾多的使用者!
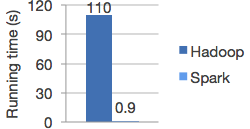
根據Apache Spark官方網站的說明,Spark在記憶體內執行運算時,最快可以比Hadoop MapReduce快100倍。即使與MapReduceㄧ樣將運算結果儲存在硬碟上,運算速度也可以快上10倍。
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
From: https://spark.apache.org/
由於Apache spark主打的是Lightning-fast cluster computing,輕量又快速的叢集運算,小至個人PC大到企業級伺服器,只要透過設定皆可以在這些機器上使用Spark來進行運算。
運算方式
Apache Spark是一個分散式的運算框架(Framework),可分為以下幾種執行運算的方法,後面的文章會介紹這幾種執行方式的方法與差別。
- local mode
- Standalone
- On Hadoop Yarn
- On Apache Mesos
Spark Api
目前Spark Api所支援的語言有:
- Scala
- Java
- Python
- R
由於Spark原始碼是以Scala撰寫,所以在Scala Api的支援相較於其他語言比較完整,其次為Java、Python、R。建議使用Scala撰寫Spark Application 可以使用完整的Spark Api,未來若有機會trace source code也比較看得懂。
Components
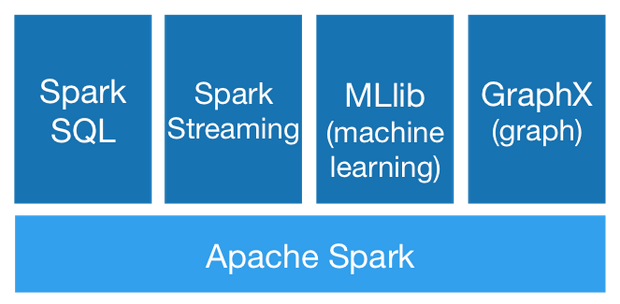
Spaek主要包含四個函式庫的功能:
- Spark SQL
- Spark Streaming
- MLlib(machine learning)
- GraphX(graph)
From: https://spark.apache.org/
在Spark的篇章會介紹Spark SQL與Spark Streaming。
最後
簡單介紹完Apache Spark,接下來會針對下面的內容做更詳細的介紹:
- Spark的核心 - RDD (Resilient Distributed Dataset)
- Spark Shell
- 使用Spark api撰寫第一個Hello World application
- 執行Spark Application - Spark Submit
- Spark SQL
- Spark Streaming
